

Американские ученые декодер для преобразования мозговой активности в речь. Технология может фактически вернуть голос людям, которые потеряли его из-за паралича, бокового амиотрофического склероза и болезни Паркинсона.
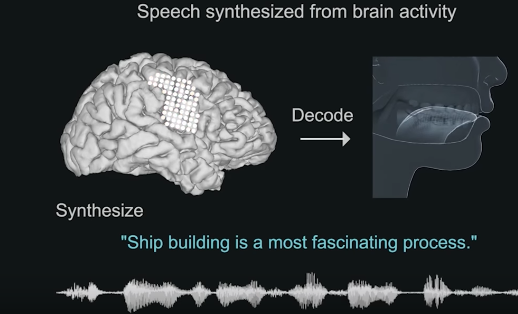

«Впервые мы можем генерировать целые предложения, основанные на активности мозга человека, — сказал ведущий автор исследования Эдвард Чанг (Edward Chang) из Калифорнийского университета в Сан-Франциско. — Это волнующее доказательство того, что с технологией, которая уже находится в пределах досягаемости, мы может создать устройство, которое вернет речь пациентам».
Синтезаторы речи, подобные тому, что использовал покойный Стивен Хокинг, обычно предполагают написание слов по буквам, используя движения глаз или лицевых мышц. Они позволяют людям озвучивать свои мысли, но по сравнению с естественной речью происходит это очень медленно. Если человек говорит в среднем 120–150 слов в минуту, то существующие технологии позволяют озвучить лишь восемь слов в минуту.
Предыдущие попытки искусственно перевести мозговую активность в речь в основном были направлены на то, чтобы понять, как звуки речи зарождаются в мозге. В новом исследовании нейробиологи выбрали иной путь. Они сконцентрировались на областях мозга, которые посылают инструкции, необходимые для координации последовательности движений языка, губ, челюсти и горла во время речи.
Команда набрала пять добровольцев, которым предстояло пройти нейрохирургическое лечение эпилепсии. При подготовке к операции врачи временно имплантировали электроды в мозг, чтобы отобразить источники судорог пациентов. Пока электроды оставались на месте, добровольцев попросили прочитать вслух несколько сот предложений, в то время как ученые записали активность областей мозга, которые участвует в производстве речи. Цель состояла в том, чтобы декодировать речь, используя двухэтапный процесс: перевод электрических сигналов мозга в голосовые движения, а затем перевод этих движений в речевые звуки.
С помощью алгоритма машинного обучения ученые получили возможность сопоставлять паттерны электрической активности мозга с голосовыми движениями, такими как сжатие губ, сжатие голосовых связок и перемещение кончика языка к нёбу. В результате удалось обучить нейросеть распознавать активность задействованных во время общения областей мозге и синтезировать их в речь. Образцы речи звучат как обычный человеческий голос, напоминающий говорящего с сильным иностранным акцентом.
Проверка разборчивости такой речи на добровольцах показала, что слушатели могут абсолютно точно транскрибировать услышанные предложения в 43% случаев. Отмечается, что труднее всего декодеру давались звуки <b > и <p >, а другие звуки воспроизводились довольно точно. Также удалось вполне хорошо передать интонацию говорящего. Ученые считают это хорошим результатом, ведь в повседневной жизни мы привыкаем к особенностям и дефектам речи говорящего, поэтому существующие недостатки прототипа не обязательно затруднят общение.
